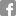3D Object in Clutter Recognition and Segmentation

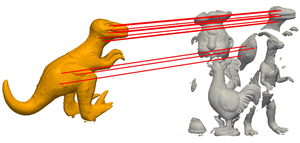
This dataset focuses on the recognition of known objects in cluttered and incomplete 3D scans. It is composed of 150 synthetic scenes, captured with a (perspective) virtual camera, and each scene contains 3 to 5 objects. The model set is composed of 20 different objects, taken from different sources and then processed in order to obtain comparably smooth surfaces of almost uniform 100-350k triangles with an average resolution of 1.0.
The dataset features some original shapes (faces) specifically designed for the task by Matteo Sala.
If you use the dataset, please cite the following paper:
A Scale Independent Selection Process for 3D Object Recognition in Cluttered Scenes
E. Rodola, A. Albarelli, F. Bergamasco, and A. Torsello
International Journal of Computer Vision (IJCV), vol. 102, 2013

Format
The model objects as well as the range scenes come as standard binary PLY files. If you use Matlab, all scenes and models are loaded correctly with this loader using the 'tri' option (part of the PLY_IO toolkit). If you have any problems loading the files, please contact us.
The ground-truth .txt files specify, for each scene, the number of models appearing into it and the rigid motion bringing each model to its scene position. Each model is described by a line containing the model name, the rotation matrix row-major, and the translation vector, i.e.:
[model name] [R00 R01 R02 R10 R11 R12 R20 R21 R22] [T0 T1 T2]
Each scene comes with a .segments file containing segmentation labels for each scene point, in the same order as they appear in the PLY file. The labels are simply integer numbers specifying the model objects to which scene vertices belong; each number refers to the order of appearance of the model in the ground-truth .txt file, starting from 1 (for example, the label 2 indicates the second model in the .txt). The label 0 can be safely ignored an must be skipped when processing the segmentation file. The initial header of each file has the following meaning:
[resolution] [z-gap] [total # vertices] [# models] [# vertices model 1] [# vertices model 2] … [# vertices model N]
Finally, occlusion_clutter.txt contains ground-truth occlusion and clutter for each model in each scene, defined as follows:
occlusion = 1 - (visible object area) / (total object area)
clutter = 1 - (visible object area) / (total scene area)
Notes
- This dataset is designed to be challenging. It contains many smooth (feature-less) as well as similar objects (e.g., david2 vs victoria3 or horse7 vs centaur1), that should provide enough room for false positives even under low levels of occlusion and clutter. Additionally, some scenes present intersecting surfaces, which will induce spurious descriptors and keypoints for feature-based methods.
- The scenes as they are have no additional sensor-like noise applied to them, in order to give more freedom of use in your experiments. To better simulate a scanning process, you might want to apply depth positional noise to the scene vertices.
- Ground-truth occlusion and clutter might be under-estimated due to some models having internal vertices (gun0026), which cannot be captured by any range image. However, the error is negligible.